
Packet-Oriented Streamline Tracing on Modern SIMD Architectures
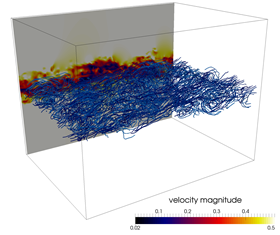
The advection of integral lines is an important computational kernel in vector field visualization. We investigate how this kernel can profit from vector (SIMD) extensions in modern CPUs. As a baseline, we formulate a streamline tracing algorithm that facilitates auto-vectorization by an optimizing compiler. We analyze this algorithm and propose two different optimizations. Our results show that particle tracing does not per se benefit from SIMD computation. Based on a careful analysis of the auto-vectorized code, we propose an optimized data access routine and a re-packing scheme which increases average SIMD efficiency. We evaluate our approach on three different, turbulent flow fields. Our optimized approaches increase integration performance up to 5:6 over our baseline measurement. We conclude with a discussion of current limitations and aspects for future work.
@INPROCEEDINGS{Hentschel2015,
author = {Bernd Hentschel and Jens Henrik G{\"o}bbert and Michael Klemm and
Paul Springer and Andrea Schnorr and Torsten W. Kuhlen},
title = {{P}acket-{O}riented {S}treamline {T}racing on {M}odern {SIMD}
{A}rchitectures},
booktitle = {Proceedings of the Eurographics Symposium on Parallel Graphics
and Visualization},
year = {2015},
pages = {43--52},
abstract = {The advection of integral lines is an important computational
kernel in vector field visualization. We investigate
how this kernel can profit from vector (SIMD) extensions in modern CPUs. As a
baseline, we formulate a streamline
tracing algorithm that facilitates auto-vectorization by an optimizing compiler.
We analyze this algorithm and
propose two different optimizations. Our results show that particle tracing does
not per se benefit from SIMD computation.
Based on a careful analysis of the auto-vectorized code, we propose an optimized
data access routine
and a re-packing scheme which increases average SIMD efficiency. We evaluate our
approach on three different,
turbulent flow fields. Our optimized approaches increase integration performance
up to 5.6x over our baseline
measurement. We conclude with a discussion of current limitations and aspects
for future work.}
}
