
Using Directed Variance to Identify Meaningful Views in Call-Path Performance Profiles
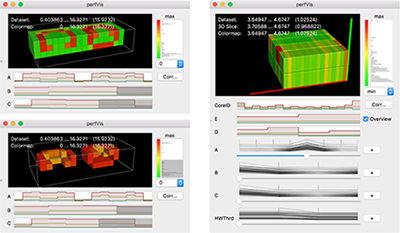
Understanding the performance behaviour of massively parallel high-performance computing (HPC) applications based on call-path performance profiles is a time-consuming task. In this paper, we introduce the concept of directed variance in order to help analysts find performance bottlenecks in massive performance data and in the end optimize the application. According to HPC experts’ requirements, our technique automatically detects severe parts in the data that expose large variation in an application’s performance behaviour across system resources. Previously known variations are effectively filtered out. Analysts are thus guided through a reduced search space towards regions of interest for detailed examination in a 3D visualization. We demonstrate the effectiveness of our approach using performance data of common benchmark codes as well as from actively developed production codes.
@inproceedings{VIERJAHN-2016-04,
Author = {Vierjahn, Tom and Hermanns, Marc-Andr\'{e} and Mohr, Bernd and M\"{u}ller, Matthias S. and Kuhlen, Torsten W. and Hentschel, Bernd},
Booktitle = {3rd Workshop Visual Performance Analysis (to appear)},
Title = {Using Directed Variance to Identify Meaningful Views in Call-Path Performance Profiles},
Year = {2016}}
